
HTTP 1.0 is a fast, stateless protocol for the exchange of textual information. "Stateless", in this context, means that the server doesn't remember any information about a query after it has been responded to. In NNTP, for example, a state-bound protocol, the client usually issues a GROUP command to specify a newsgroup to read. The server switches to that group, and applies the next command the client issues in the context of the current group. HTTP, however, is amnesiac; if you send two commands to an HTTP server, the result of the first command should not in any way affect the second command (except in some limited, unusual, circumstances: for example, when a CGI script is tracking state information associated with a browser's interaction with the server).
An HTTP exchange takes place over a TCP/IP socket. The client
opens a socket, connects to the HTTP server via the port the server
is listening to, and issues a command. The command is routed to
the server via the internet. The server receives the command and
does something, typically involving a file lookup.
Stage One: the client makes a request
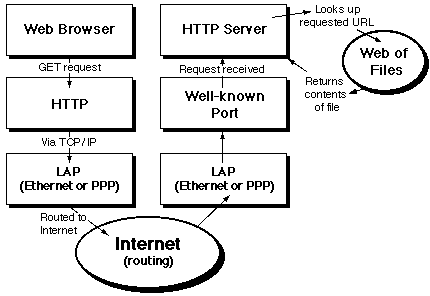
Stage two: the server returns a file
The second part of the transaction occurs when the server encodes the results of the request as a MIME-encapsulated document, pumps it back down the socket, then closes the connection. What happens after that is typically up to the client: normally it parses the response and either issues another query or renders the response and displays it.
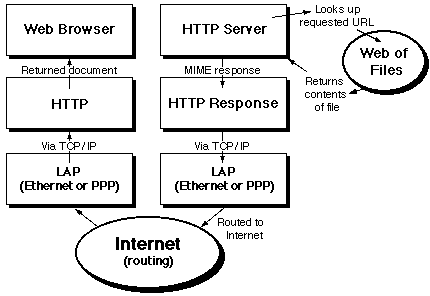
Types of HTTP request
There are two types of HTTP request: simple requests, and full requests. A simple request is a command to get a URI. For example:
GET http://info.cern.ch/<CR><LF>
where <CR> is a carriage return character; <LF> is a line feed character.
The server's response is to send the object specified by the GET request back to the client via the socket. In the case of a simple request, the object is simply sent back to the browser. In the event of a full request, the object is encapsulated using the MIME protocol, and a descriptive header precedes it on its way to the client.
MIME is the internet standard for multi-media electronic mail, and it is described in the internet standards documents RFC1521 and RFC1522 (formerly RFCs 1341 and 1342) . Because a lot of mail gateways and network connections cannot handle full 8-bit binary data, or even 8-bit text, or long lines of text, MIME "encapsulates" files for transport; a MIME message consists of a header (specifying the encoding method used) and an encoded form of the file, that is intended to pass through any mail gateway, however primitive.
For example, a valid MIME content-type might be:
Application/postscript
Indicating that the file in question contains application-specific information, of type postscript.
Use of the MIME protocol gives HTTP two advantages. Firstly, it can send ASCII-only connections, and handle data passed through email gateways. Secondly, it serves to identify the type of data in the transmission. HTTP is not restricted to sending HTML; the MIME header identifies the method that must be used to unpack the document, andthe format of the document.
(We will examine the implications of MIME encoding in more detail later in this chapter.)
A full request is somewhat more complex. It is a text message
from the client, encoded in accordance with RFC-822 (originally
used to define the header of email messages). It has this form:
Method URI ProtocolVersion <CR><LF> [*<HTRQ Header>] [<CR><LF> <data>] |
"Method" is actually a command to the server. GET is a method; there are others, and we'll see them shortly.
"URI" is short for Universal Resource Indicator. At present, this is just a URL; however, the URI specification subsumes URLs and other, as yet unused, types of resource. (We'll see more about URIs in chapters 4 and 6.)
"ProtocolVersion" is usually a fixed piece of text that indicates the version of the protocol in use. At present it is "HTTP/1.0", but this allows for change when HTTP 1.1 and HTTP-NG become available. (These future protocols are described later.)
Here is an example full request:
METHOD GET http://info.cern.ch/ HTTP/1.0<CR><LF>
The "METHOD GET" part of the request indicates that it is a GET request, as opposed to a POST or PUT or some other type. The "HTTP/1.0" following the URI indicates that the request uses the HTTP 1.0 protocol.
The HTRQ Header is an optional element or elements, separated by <CR><LF> pairs. They are encoded in RFC-822 format, so that each line consists of a keyword, followed by a colon, then a value or values. They are used to transmit control information about the transaction (such as who it originates from, what types of MIME-encoded data the client can accept, how they should be encoded, and what language version to send if the document specified by the GET command is available in multiple versions in different languages.)
The "Data" portion is optional. Again, it consists of a MIME-encoded message. It is determined by the earlier information in the request; for example, a PUT command (which uploads a URL to a server) supplies the file to upload in the data portion of the request.
Methods
The method determines what the server is to do with the URL supplied in the query. Many methods are possible; you can extend the list and add new methods, by registering them with the central registration authority. Here are the commonest: note that they are case-sensitive (unlike URIs).
| GET | Retrieve whatever is indicated by the URI. If the URI points to a file, the server should return the file. If it points to a CGI script, the server should execute the script (with the remainder of the URI passed as parameters) and return the scripts output. |
| HEAD | Retrieve the HEAD portion of the specified URI. The HEAD portion of an HTML file stores various information, including some tags not discussed in the preceding chapter; notably, you can use it to store an indication of the last modification date. HTML HEAD elements are typically much smaller than the BODY elements. This command is really useful for cacheing web clients that store HTML files after each lookup, such as Netscape. When visiting a file that is stashed in the local cache, the web client grabs the HEAD of the file and checks the modification date. If it has been modified since it was last loaded (and stored in the cache), the browser issues a GET command to retrieve the body; otherwise, it displays the locally stored copy (which saves net bandwidth and time). |
| POST | Used to send a file, or data, to the server. The data is MIME-encapsulated, and may be stored on the server as a file (if the server is so configured). Used by fill-out forms to send large amounts of data to a server. If the POSTed data is used to create a file, a URL corresponding to the new document is created and returned to the client. |
| PUT | Stores the information in the body portion of the request under the specified URL (which must already exist -- typically created by a POST command). (Not commonly implemented.) |
| DELETE | Causes the server to delete the information stored under the specified URL.(This causes the URL to become invalid for future requests). (Virtually never implemented, for security reasons.) |
| TEXTSEARCH | The specified URL is to be searched, using the query part of the URL (i.e.,the chunk following a question-mark in the URL). (Searching will be covered in detail later in this book. This method is virtually never implemented as such.) |
Several other methods are available.
LINK and UNLINK are used to connect or disconnect objects from each other.
SPACEJUMP is used to indicate that the target of a GET method accepts a query consisting of the coordinates of a point within the object; this is used in implementing image maps.
CHECKIN and CHECKOUT are similar to PUT and GET, but lock the object being checked in or out against changes by other users; they are deprecated, but were originally intended to facilitate common document source code management (such as a distributed version control engine).
These methods are not actually used by most servers, because they imply a degree of interactivity that is inappropriate to the web's current usage model as a publishing medium. They are an historic legacy of the early web, which was implemented at CERN as a platform for collaborative working ñ the idea being that the web server would not be merely a publishing mechanism, but a project tracking and version control system with build-in text searching.
HTTP Request Fields
These fields are included in the query in a form similar to headers in an RFC-822 specification email message. Their function is to modify (or clarify) a method. Standard request fields are:
| From: | Identifies the username of the originator of the query. (Note that this is not trusted for secure communications.) |
| Accept: | Contains a semi-colon separated list of
content-types that the browser can accept and format. (Content-types are
defined within MIME; see below for more information.) To save time it is
possible to use wildcards in the Accept: field; for example:
Accept: text.* |
| Accept-Encoding: | Contains a semi-colon separated list of content-types that the browser can handle in the response. (For example, files that can be received and saved locally.) The Accept-encoding field does not necessarily imply the ability to parse or display that content-type. |
| User-Agent: | Contains the name of the browser or spider (web-probing robot) that originated the query. (This doesn't influence the returned response, but is used to provide the server with statistical information.) |
| Referrer: | If present, contains the URL of the document from which the current query is derived. For example, if you are browsing a document (X) andselect a URL (Y), the Referrer: field in your browser's HTTP request should be set to the URL of (X). |
| Authorization: | Used for password/username/encryption information. |
| Charge-To: | Used for account information; tells the server who to bill the request to. (The definition of this field is still being refined.) |
| If-Modified-Since: | This field can be used to make
a GET command conditional. If you are using a cacheing browser which saves
visited files locally, it can use this field to ensure that the file is only
resent if it has been modified since the last time a local copy was stored. (It
obtains the date at which the copy in its cache was written; puts that date in
the If-Modified-Since: field; and if nothing is returned, knows that it is safe
to display the version in the cache because it is still current.)
Note that the format for dates is specified in the HTTP protocol. Dates are presented in a regular format, like: Tue, 15 Nov 1994 08:12:31 GMT. |